-
首页
-

- 首页
- 新闻
国发院学术下午茶系列讲座第二讲举办
发布日期:2022-10-20 06:48 来源:
本学期,国家发展研究院开始举办学术下午茶系列讲座。活动旨在推动国发院师生内部跨领域交流,鼓励老师们分享新的研究想法,促进思想的交流和潜在的学术合作。下午茶系列讲座已成功于2022年10月10日举办第一次,主题是卫生经济学中的道德风险问题,由黄炜老师分享。本次下午茶是本系列的第二次活动,于2022年10月17日在承泽园研究生活动室开展,由国发院和南南学院助理教授刘诗尧作为分享嘉宾,围绕统计学和计量经济学中的“测量误差”概念,分三个方面对自己的研究及学术前沿进行了介绍。老师和同学们在本次活动中进行了充分的讨论和交流,现场氛围轻松活跃,碰撞出了无数的思维火花,产生了许多新的研究想法。

10月17日下午3至4时,刘诗尧老师作为第二次下午茶的讲座嘉宾,为大家带来了内容丰富的介绍。刘诗尧老师学术研究领域主要包括与测量误差相关的统计计量研究以及中国政治和政治行为的比较政治学研究。整场下午茶将分为三个部分,结合刘诗尧老师自己研究的最新进展,为大家讲解测量误差问题在统计学和计量经济学领域的研究前沿。
作为引入,刘诗尧老师首先为大家简单回顾了测量误差出现的原因。如下图所示:
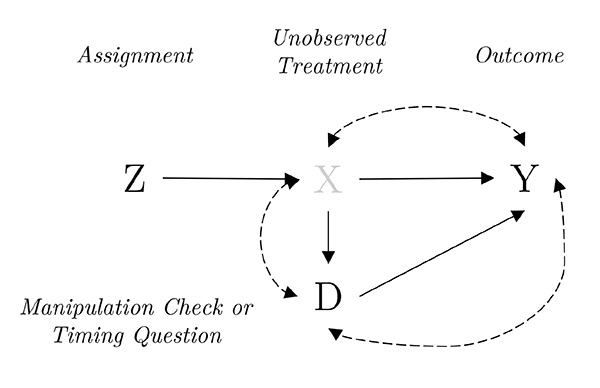
为了评估实验的处理效应(Treatment effect),我们需要知道哪些个体受到了处理(Treatment),而哪些个体没有,在上图中表示为X=1或X=0。但是,在经济学研究中,很多时候我们观测不到个体有没有接受处理,只能通过一个代理变量D间接地判断某个个体是否接受了处理。此时,便会出现测量误差,从而导致估计出来的系数存在衰减偏误(Attenuation bias)。
测量误差问题是普遍存在的,在许多经济学研究中都非常常见。接下来,在讲座的第二个部分中,刘诗尧老师以自己最近的一篇正在进行中的研究为例,为大家说明了测量误差在参数估计中的影响。
第二个部分的讲解围绕效力分析(Power analysis)展开,主要基于刘诗尧老师与Teppei Yamamoto共同开展的研究《How Much Should You Trust Your Power Calculation Results: Power Analysis as an Estimation Problem》。在做经济学实验之前,研究者需要使用效力分析决定实验样本量大小。效力(Power)就是不犯第二类错误的概率。举例来说,假设样本真的存在处理效应,那么效力等于80%就意味着有80%的可能可以识别出这个处理效应。在效力分析中,一般需要用到3个变量,分别是(1)标准化后的处理效应大小(Standardized effect size)、(2)样本量(Sample size)和(3)效力。给定其中两者,第三者可以被计算出来。计算方法共有三种:(1)传统的效力计算(Conventional power calculation);(2)最小样本需求量算法(Minimum Required Sample Size, MRSS),即给定标准化的处理效应大小以及想要的效力,求最小样本量;(3)最小可检测效应大小算法(Minimum Detectable Effect Size),即给定样本和想要的效力水平,求出可以测出来的标准化处理效应是多少。其中,方法(3)是本研究推荐的做法。不同于作为计算(Calculation)过程的方法(1)和(2),方法(3)将标准化后的处理效应大小假设为未知的,使效力成为一个估计(Estimation)结果,避免了在实验前就需要对处理效应做假设的悖论。
然而,处理效应的估计量很可能不是无偏的;并且,由于使用处理效应估计量来得到效力估计量的过程中经过了标准正态分布的函数变换,导致即使处理效应估计量是无偏的,效力估计量也可能有偏。此外,因为正态分布的累积分布函数既不是凸函数、也不是凹函数,故不能判断效力估计量是高估还是低估。
经济学和政治学随机控制实验(Randomized Controlled Trial, RCT)中,在大规模实施实验前,需要先在小范围内进行实验,收集试点样本(Pilot sample),并计算试点处理效应,随后再进行完整实验(Full experiment)。刘诗尧老师对于不同试点样本量及完整样本量下效力估计值的偏差进行了数值模拟,其中部分结果如下所示:

由于试点样本和完整样本分别取50、900或50、1300是比较符合现实的,因此我们可以主要考察上图中靠右的两条曲线。刘诗尧老师收集了2015年以来发表在四个顶级政治学期刊上的所有RCT研究的结论,取出全部的处理效应估计值,并对其进行了标准化处理。他发现,标准化后的处理效应估计值中位数为0.25。因此,从图中可以看出,发表在比较好的政治学期刊上的RCT文章,其效力估计平均而言会存在低估,大约存在20个百分点的偏差,换算成百分比大约是25%。遗憾的是,刘诗尧老师发现,使用Bootstrap、Jackknife以及Double Bootstrap等多种偏差调整方法,都不能很好地缩小这个偏差。
谈到本篇研究如何改进时,许多与会老师都提出了宝贵的建议。王轩老师建议计算出偏误的阶数。雷晓燕老师建议给出试点样本量与完整样本量的最优比例。于航老师认为,当我们进行效力分析的时候,我们关心的不是偏误大小,而是两种无谓损失(Deadweight loss):其一,是在小样本时就可以得出结论,却设计了过大的样本量,导致研究者要么放弃了实验,要么消耗了本来可以节约的成本;其二,是结论对样本量需求较大,但设计实验时样本量过小,导致得不出任何统计上显著性较强的结论。因此,于航老师建议关注在分布上处于尾部(Tail)的样本量,即较大或较小的样本量。
在第三部分中,刘诗尧老师简要介绍了自己与清华大学孟天广长聘副教授合作的一篇文章《What Makes a Government Respond? Learning for Texts as a Measurement beyond Topics》所使用的数据及方法。该文章使用北方某城市若干年的群众来信全文,采用自然语言处理中的话题模型(Topic Model)对所有信件文本进行分类,按来信原因分成不同的10个类别。他认为,采用无监督机器学习对文本进行分类的效果不佳;采用有监督学习则需要涉及对测量误差进行调整和校准。

最后,刘诗尧老师对整场讲座进行了简要总结:对于经典测量误差而言,其出现在因变量上是没关系的,而如果出现在自变量上,就会出现衰减偏误。建议大家在做任何估计时,都要考虑一下估计量的不确定性。
(文字:张想)
国家发展研究院官方微信
Copyright© 1994-2012 北京大学 国家发展研究院 版权所有, 京ICP备05065075号-1
保留所有权利,不经允许请勿挪用
-
首页
-
国发院学术下午茶系列讲座第二讲举办
发布日期:2022-10-20 06:48 来源:
本学期,国家发展研究院开始举办学术下午茶系列讲座。活动旨在推动国发院师生内部跨领域交流,鼓励老师们分享新的研究想法,促进思想的交流和潜在的学术合作。下午茶系列讲座已成功于2022年10月10日举办第一次,主题是卫生经济学中的道德风险问题,由黄炜老师分享。本次下午茶是本系列的第二次活动,于2022年10月17日在承泽园研究生活动室开展,由国发院和南南学院助理教授刘诗尧作为分享嘉宾,围绕统计学和计量经济学中的“测量误差”概念,分三个方面对自己的研究及学术前沿进行了介绍。老师和同学们在本次活动中进行了充分的讨论和交流,现场氛围轻松活跃,碰撞出了无数的思维火花,产生了许多新的研究想法。
10月17日下午3至4时,刘诗尧老师作为第二次下午茶的讲座嘉宾,为大家带来了内容丰富的介绍。刘诗尧老师学术研究领域主要包括与测量误差相关的统计计量研究以及中国政治和政治行为的比较政治学研究。整场下午茶将分为三个部分,结合刘诗尧老师自己研究的最新进展,为大家讲解测量误差问题在统计学和计量经济学领域的研究前沿。
作为引入,刘诗尧老师首先为大家简单回顾了测量误差出现的原因。如下图所示:
为了评估实验的处理效应(Treatment effect),我们需要知道哪些个体受到了处理(Treatment),而哪些个体没有,在上图中表示为X=1或X=0。但是,在经济学研究中,很多时候我们观测不到个体有没有接受处理,只能通过一个代理变量D间接地判断某个个体是否接受了处理。此时,便会出现测量误差,从而导致估计出来的系数存在衰减偏误(Attenuation bias)。
测量误差问题是普遍存在的,在许多经济学研究中都非常常见。接下来,在讲座的第二个部分中,刘诗尧老师以自己最近的一篇正在进行中的研究为例,为大家说明了测量误差在参数估计中的影响。
第二个部分的讲解围绕效力分析(Power analysis)展开,主要基于刘诗尧老师与Teppei Yamamoto共同开展的研究《How Much Should You Trust Your Power Calculation Results: Power Analysis as an Estimation Problem》。在做经济学实验之前,研究者需要使用效力分析决定实验样本量大小。效力(Power)就是不犯第二类错误的概率。举例来说,假设样本真的存在处理效应,那么效力等于80%就意味着有80%的可能可以识别出这个处理效应。在效力分析中,一般需要用到3个变量,分别是(1)标准化后的处理效应大小(Standardized effect size)、(2)样本量(Sample size)和(3)效力。给定其中两者,第三者可以被计算出来。计算方法共有三种:(1)传统的效力计算(Conventional power calculation);(2)最小样本需求量算法(Minimum Required Sample Size, MRSS),即给定标准化的处理效应大小以及想要的效力,求最小样本量;(3)最小可检测效应大小算法(Minimum Detectable Effect Size),即给定样本和想要的效力水平,求出可以测出来的标准化处理效应是多少。其中,方法(3)是本研究推荐的做法。不同于作为计算(Calculation)过程的方法(1)和(2),方法(3)将标准化后的处理效应大小假设为未知的,使效力成为一个估计(Estimation)结果,避免了在实验前就需要对处理效应做假设的悖论。
然而,处理效应的估计量很可能不是无偏的;并且,由于使用处理效应估计量来得到效力估计量的过程中经过了标准正态分布的函数变换,导致即使处理效应估计量是无偏的,效力估计量也可能有偏。此外,因为正态分布的累积分布函数既不是凸函数、也不是凹函数,故不能判断效力估计量是高估还是低估。
经济学和政治学随机控制实验(Randomized Controlled Trial, RCT)中,在大规模实施实验前,需要先在小范围内进行实验,收集试点样本(Pilot sample),并计算试点处理效应,随后再进行完整实验(Full experiment)。刘诗尧老师对于不同试点样本量及完整样本量下效力估计值的偏差进行了数值模拟,其中部分结果如下所示:
由于试点样本和完整样本分别取50、900或50、1300是比较符合现实的,因此我们可以主要考察上图中靠右的两条曲线。刘诗尧老师收集了2015年以来发表在四个顶级政治学期刊上的所有RCT研究的结论,取出全部的处理效应估计值,并对其进行了标准化处理。他发现,标准化后的处理效应估计值中位数为0.25。因此,从图中可以看出,发表在比较好的政治学期刊上的RCT文章,其效力估计平均而言会存在低估,大约存在20个百分点的偏差,换算成百分比大约是25%。遗憾的是,刘诗尧老师发现,使用Bootstrap、Jackknife以及Double Bootstrap等多种偏差调整方法,都不能很好地缩小这个偏差。
谈到本篇研究如何改进时,许多与会老师都提出了宝贵的建议。王轩老师建议计算出偏误的阶数。雷晓燕老师建议给出试点样本量与完整样本量的最优比例。于航老师认为,当我们进行效力分析的时候,我们关心的不是偏误大小,而是两种无谓损失(Deadweight loss):其一,是在小样本时就可以得出结论,却设计了过大的样本量,导致研究者要么放弃了实验,要么消耗了本来可以节约的成本;其二,是结论对样本量需求较大,但设计实验时样本量过小,导致得不出任何统计上显著性较强的结论。因此,于航老师建议关注在分布上处于尾部(Tail)的样本量,即较大或较小的样本量。
在第三部分中,刘诗尧老师简要介绍了自己与清华大学孟天广长聘副教授合作的一篇文章《What Makes a Government Respond? Learning for Texts as a Measurement beyond Topics》所使用的数据及方法。该文章使用北方某城市若干年的群众来信全文,采用自然语言处理中的话题模型(Topic Model)对所有信件文本进行分类,按来信原因分成不同的10个类别。他认为,采用无监督机器学习对文本进行分类的效果不佳;采用有监督学习则需要涉及对测量误差进行调整和校准。
最后,刘诗尧老师对整场讲座进行了简要总结:对于经典测量误差而言,其出现在因变量上是没关系的,而如果出现在自变量上,就会出现衰减偏误。建议大家在做任何估计时,都要考虑一下估计量的不确定性。
(文字:张想)

